 会員登録
会員登録 ログイン
ログイン

構造化データは、コンテンツに記載された文字の意味や意図を検索エンジンに理解してもらうための手法です。2015年にGoogleのジョン・ミューラー氏がオフィスアワーで発言したように、検索順位の上昇に直接的な影響力はないとされていますが、実装することによってユーザーのクリック数増加を図れるため、重要視されています。しかし、実際にどのように導入すれば良いのか、詳しく知らない方もいるでしょう。
そこで今回は、構造化データの基本から、導入のメリットと注意点、具体的な記述方法やマークアップ後の検証方法までを解説します。
目次
構造化データの基本
まずは構造化データを深く理解するために、基本的な事項について確認していきましょう。
構造化データとは?
検索エンジンはコンテンツの内容を理解できません。そこで、HTMLに書かれた情報にタグ付けを行い、検索エンジンが文字や画像の内容、意図を読み解けるようにしたものが構造化データです。
構造化データは、テキストを単なる文字情報として蓄積するのではなく、検索エンジンに意味や背景も理解させ、知識として蓄積しようとする「セマンティックWeb」の試みを実現するための一つの手段です。
構造化データはボキャブラリーとシンタックスで記述する
構造化データを理解するためには、「ボキャブラリー」と「シンタックス」という二つの用語の意味も押さえておきましょう。
ボキャブラリー
構造化データを記述する際は、マークアップする対象が何を表しているのか定義する必要があり、そのための規格がボキャブラリーです。
代表的なボキャブラリーは、Google、Yahoo!、Bing、Yandexの共同開発による規格「schema.org」と、その前身の「data vocabulary」の二つです。Googleは「data vocabulary」にも対応していますが(2018年1月時点)、公式ページに記載がないことから、記述する際は「schema.org」を利用したほうが良いでしょう。
シンタックス
構造化データをマークアップする際の記述方法がシンタックスといわれるもので、「JSON-LD」「Microdata」「RDFa」の3つが代表的です。
「JSON-LD」は2014年1月にW3C(World Wide Web Consortium)の勧告となったオープンデータフォーマットで、一カ所で構造化データを記述できるメリットがあります。Googleも「JSON-LD」の使用を推奨しており、2015年以降はサポートを増加して、当初は対応していなかったパンくずリスト、レビュー、評価などにも対応可能となっています。
「Microdata」と「RDFa」はデータに直接マークアップするタイプのシンタックスです。「Microdata」はHTML5で使用することができますが、2013年10月でW3Cの勧告が停止しています。「RDFa」はHTML5のほか、XHTMLなど幅広い言語で使用でき、なおかつW3Cが推奨しています。
構造化データを実装するメリットとは?
構造化データをマークアップすると、検索結果の表示方法を変えることができます。直接的には検索順位に影響しませんが、特にモバイルにおける検索結果の表示を大きく変えられます。構造化データのマークアップにより可能となる表示方法は、次の3つです。
リッチスニペットを表示できる
リッチスニペットとは、通常のスニペットにパンくずリストやレビュー、サムネイル画像などの情報が加わって表示されているものです。例えば、飲食店を検索エンジンで検索した際に表示される、「食べログ」や「ぐるなび」といったグルメサイトの評価(星マーク)が挙げられます。ユーザーに対して、より視覚的にコンテンツの内容をアピールできるでしょう。
リッチカードを表示できる
リッチスニペットをよりビジュアル的に発展させたものがリッチカードです。検索窓の下にカルーセル形式で写真(動画)と記事タイトルを表示させることができます。レシピ、映画、飲食店のカテゴリーに対応しています。
※リッチカードについては、以下の記事で詳しく取り上げています。
エンリッチ検索結果へ掲載できる
通常のリッチリザルトを拡張した、双方向性のある検索結果をエンリッチ検索結果と呼びます。アメリカで導入されており、対象カテゴリーは求人、レシピ、イベントです。例えば “Marketing Jobs in Seattle”の求人検索では、該当する求人情報を検索結果上にポップアップで表示する「Google for Jobs」が発表されています。
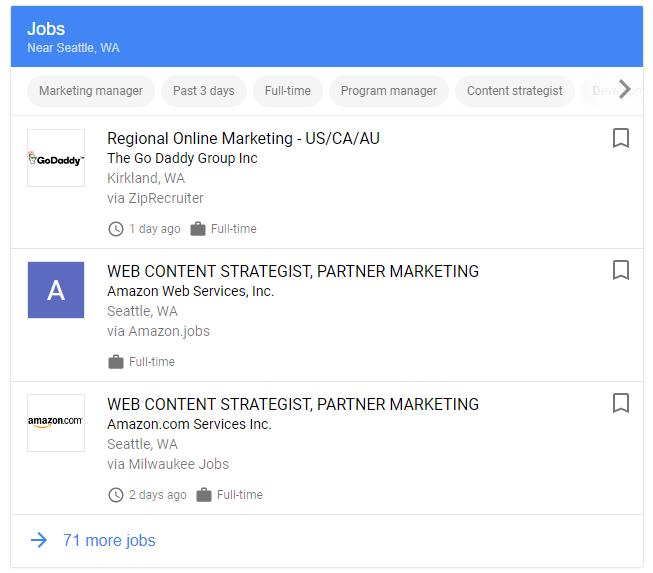
リッチスニペットやリッチカードなどは通常の検索結果よりも上に表示されるケースが多いため、クリック率(CTR)の向上を図れます。
構造化データの書き方
構造化データの具体的な記述方法について解説します。直接記述する方法と、ツールを利用する方法がありますので、それぞれ確認していきましょう。マークアップするテキストは、比較がしやすいように次の例文で統一します。
| 会社名:株式会社CINC 所在地:〒106-0032 東京都港区 六本木7-4-8 ウインドビル2F 電話番号:03-6434-5305 |
直接マークアップする
JSON-LDの記述方法
JSON-LDで例文を構造化マークアップすると、次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<script type="application/ld+json"> { "@context": "http://schema.org", "@type": "Corporation", "name": "株式会社CINC", "address": { "@type": "PostalAddress", "postalCode": "106-0032", "addressRegion": "東京都", "addressLocality": "港区", "streetAddress": "六本木7-4-8 ウインドビル2F" }, "telephone": "+81364345305", "URL": "https://www.cinc-j.co.jp/" } </script> |
では、各行が何を意味するのか、詳しく見ていきましょう。
- スクリプトタグを使って、使用するシンタックスを宣言します。
- ボキャブラリーで表す一つのものは{ }の中に書きます。このまとまりをJSONオブジェクトと呼びます。一つまたは複数のkeyとvalueの組み合わせで構成され、keyは属性、valueは値を意味します。それぞれは「:(コロン)」で区切り、「”(ダブルクォーテーション)」で囲みます。
- ボキャブラリーを宣言します。@contextは構造化データがどのような定義(ボキャブラリー)に基づくかを指します。書き方は「”@context”: “ボキャブラリー”」で固定です。
マークアップしたいデータのタイプを指定します。今回は企業に該当するため、Corporationと記述します。人物の場合はPerson、製品ならProductなど、ほかにもいくつかの種類があります。記述方法は「”@type”:”Corporation(Person、Productなど)”」となります。 - keyには名前を意味する”name”を使用します。
- 住所を詳しくマークアップするために、親子関係をEmbeddingで作成します。
(4)と同様に、まずはデータの種類を選択します。今回は住所なので、PostalAddressとなります。 - 郵便番号を示すpostalCodeを、keyに入れ、valueに値を入力します。
- addressRegionで都道府県を指定します。
- addressLocalityで市区町村を指定します。
- streetAddressで市区町村以降の住所を指定します。
- URLにサイトのリンクを入力します。
- 住所に関するデータを入力し終えたら、「}」で閉じます。
- 電話番号を指定します。国番号を含めると、より詳細にマークアップでき、日本の国番号は「+81」です。
- マークアップを終えたら、「}」で締めます。
- 最後に、スクリプトタグを使って全体を閉じれば、構造化データとなります。
Microdataの記述方法
次に、Microdataによる記述方法をご紹介します。
|
1 2 3 4 5 6 7 8 9 |
<div itemscope itemtype="http://schema.org/Corporation"> <span itemprop="name">株式会社CINC</span> <div itemprop="address" itemscope itemtype="http://schema.org/PostalAddress"> <span itemprop="postalCode">106-0032</span> <span itemprop="addressRegion">東京都</span> <span itemprop="addressLocality">港区</span> <span itemprop="streetAddress">六本木7-4-8 ウインドビル2F </span><div> <span itemprop="telephone">03-6434-5305</span> </div> |
- 初めに、シンタックスとボキャブラリーを宣言します。itemscopeがシンタックスを、itemtype以降がボキャブラリーとタイプを示しています。
- スパムタグを使って、プロパティを指定していきます。指定方法は「<span itemprop=”プロパティ名”>」となります。マークアップしたい内容だけをスパムタグで囲み、余計な文字はタグの外に置くと良いでしょう。
- 住所を詳しく指定するために、再びボキャブラリーとタイプを指定します。親子関係を作る記述法は「<span itemprop=”プロパティ” itemscope itemtype=”ボキャブラリーとタイプ”>」で固定です。
- プロパティを指定し、該当するテキストをタグで囲みます。住所情報をマークアップし終えたら、親タグを閉じる</span>も忘れずに入力してください。
- 電話番号をスパムタグで囲みます。
- すべてのテキストをマークアップできたら、</div>で閉じましょう。
RDFaの記述方法
RDFaはMicrodataと記述方法が似ていますが、一部違いがあります。
|
1 2 3 4 5 6 7 8 9 |
<div vocab="http://schema.org/" typeof="Corporation"> <span property="name">株式会社CINC </span> <div property="address" typeof=" PostalAddress"> <span property="postalCode">106-0032 </span> <span property="addressRegion">東京都</span> <span property="addressLocality">港区 </span> <span property="streetAddress"> 六本木7-4-8 ウインドビル2F </span></div> <span property="telephone">03-6434-5305 </span> </div> |
- ボキャブラリーとタイプを指定します。Microdataとは違い、vocabでボキャブラリーを宣言し、typeofでタイプを示します。
- スパムタグを使ってプロパティを指定し、構造化データにする文字を囲みます。マークアップするテキスト以外はタグの外に置きましょう。
- 住所を詳しくマークアップしていくため、再びタイプを設定します。
- 郵便番号、都道府県、市区町村、以降の住所それぞれをスパムタグで囲みます。住所情報のマークアップが終わったら、</div>タグで閉じましょう。
- 電話番号をスパムタグで囲みます。
- マークアップしたいテキストをすべて記述したら、最後に</div>で全体を閉めましょう。
マークアップしたいテキストをすべて記述したら、最後に</div>で全体を閉めましょう。
データハイライター(ウェブマスターツール)を使用する
データハイライターを使用すれば、直接HTMLに記述することなく、構造化マークアップを行うことができます。使用方法を順に追っていきましょう。
- Search Console「検索での見え方」にある「データハイライター」を開きます。
- 「ハイライト表示を開始」をクリックします。
- 構造化データを埋め込みたいWebサイトのURLを入力し、タイプを選択します。
- マークアップしたい部分をタグ付けしていきます。
- タグ付けが終わったら「完了」を選択します。
- サンプルページにて構造化されているかをチェックします。
- 問題がなければ「公開」を押して、マークアップ完了です。
構造化データを検証する方法
構造化データを設定できたら、きちんと記述できているかを確認しましょう。専用のツールを利用する方法がおすすめです。
構造化データテストツールを利用する
構造化データテストツールを利用すれば、簡単に構造化データを検証することができます。使い方は、HTMLを貼り付けるか、確認したいページのURLを入力するだけです。もし何らかのエラーが出ていたら、文法に誤りはないか、プロパティに不足はないかなど、エラー部分を探して修正しましょう。
ウェブマスターツールの「構造化データ」項目を確認する
Search Consoleの「検索の見え方」にある「構造化データ」で確認する方法もあります。構造化データテストツール同様、エラーが出ていれば記述内容を確認し、必要に応じて修正を行いましょう。
記述内容に誤りがない場合、robots.txtで検索エンジンのアクセスを拒否しているケースもあるので、設定を確認してみてください。エラーの原因が見つからなければ、ページがまだクローリングされていない可能性もあります。時間を置いて再度チェックしてみましょう。
また、Search Consoleでは、エラーが発生しているURLと具体的なエラー内容をレポートしてくれる機能も付いています。リッチカードが正しくインデックスされているかどうかや、改善できるカード数の推移などを確認することもできますので、併せて活用してみてはいかがでしょうか。
構造化マークアップは検索順位へ影響しない
構造化データをマークアップしても、直接的には検索順位に影響しないことがわかっています。ただし、検索結果の表示方法を最適化することで、コンテンツの内容を検索エンジンに正しく伝えられるため、間接的な影響はあるかもしれません。
2017年11月に開催されたPubconで、Googleのゲイリー・イリーズ氏は、2018年は構造化データに注目することをおすすめしています。「schema.org」を使用した構造化マークアップにより、エンリッチ検索結果などの検索エンジンの新しい機能はすでにリリース済みです。また、イリーズ氏はGoogleがまだ対応していない構造化データの活用を推奨していることから、今後も新しい機能が追加されると予想されます。そのため、構造化データには積極的に取り組んだほうが良いでしょう。
構造化データのマークアップは早めに対策を
構造化データはサイトの検索順位に直接は影響しません。そのため、対策が後回しになりがちですが、検索結果での表示方法が変わることによって得られるメリットもあります。まだ取り組んでいない方は、Google推奨のJSON-LDでマークアップしてみてください。最初は記述の仕方に戸惑うかもしれませんが、構造を理解すれば、意外とシンプルなことに気づくはずです。コンテンツのクリック率を上げたい方は、構造化データをマークアップして、表示方法を最適化させることから始めてみましょう。




